Determining group membership
The discriminant function model
Assumptions
Finding the discriminant function(s)
Potential problems
Determining statistical significance
Many potential topics of research center around determining
the group or population
to which a sample belongs. For example, we may have found
multiple ash layers in a sedimentary sequence and want to differentiate
their respective volcanic sources. If we measured the chemical composition
of the ash this could provide the basic information to distinguish between
the sources. Or from a financial standpoint, we might want to distinguish
growth from value stocks. Measures of variables such as the price
to earnings ratio, share price, or book value might provide some insight
by which we could differentiate these two groups.
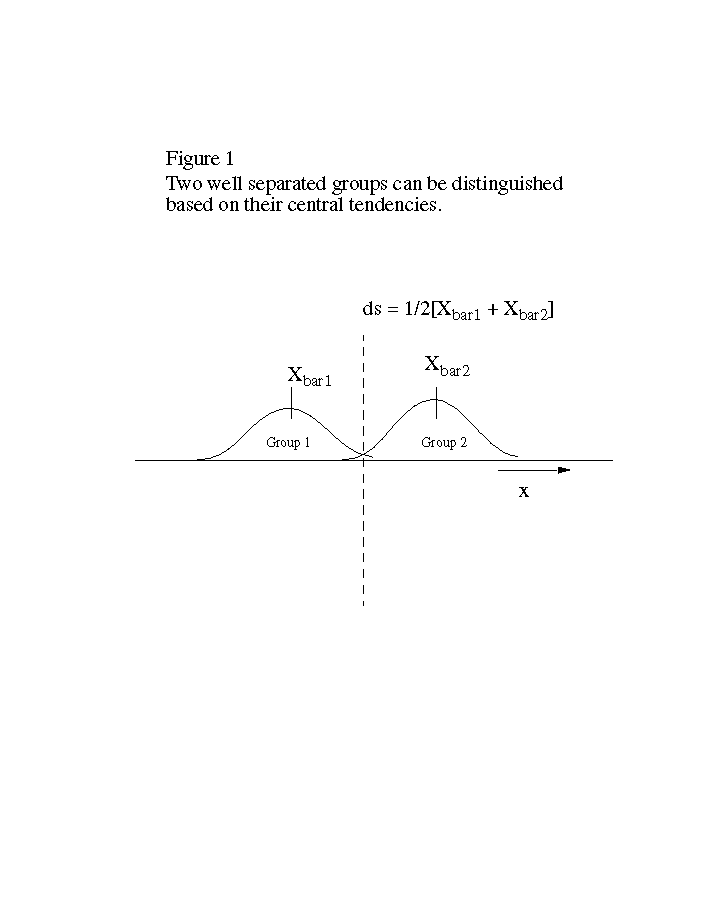
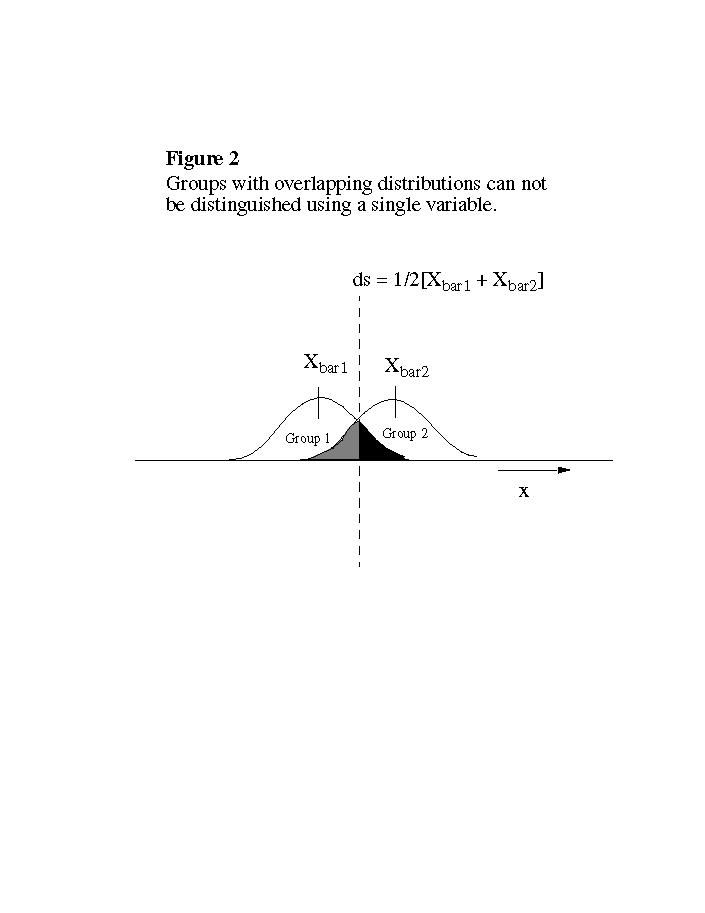
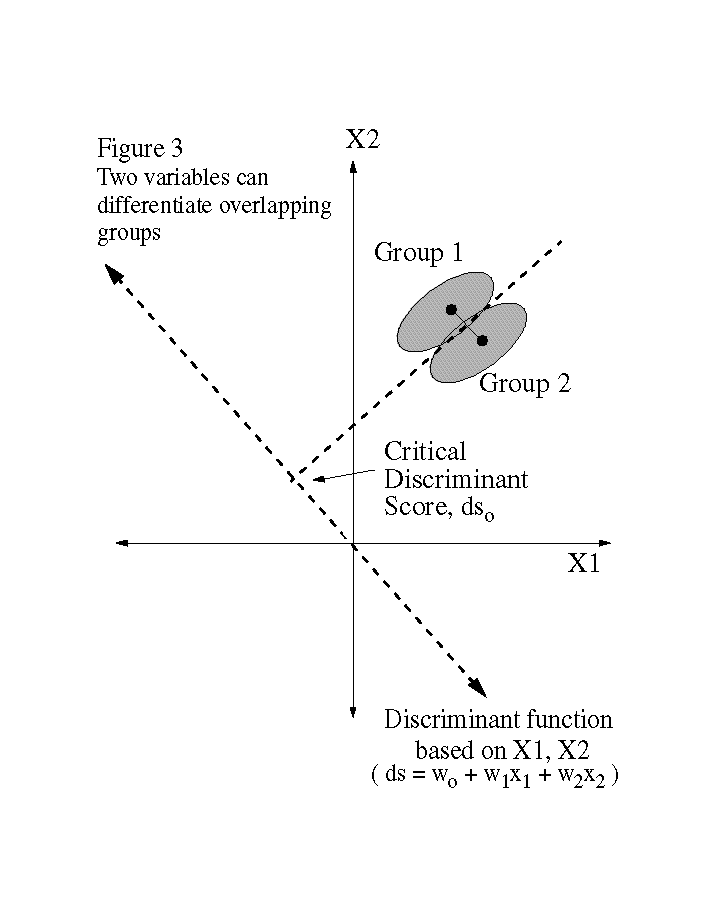
In the simplest case, measurement of a single variable might be enough to sort samples into two groups on the basis of differences in their central tendency (Figure 1). In practice, however, this is usually not the case, because the variance of the two groups may overlap significantly due to natural variability and noise (Figure 2). The obvious next step is to measure more than one variable on the same samples in the hopes that there will be less overlap between the two groups in the plane defined by the two variables (Figure 3).
Discriminant function analysis provides a means of quantifying this visual process. In the two group case where, two or more variables are manipulated to form a composite variable called a discriminant function. The methods can be generalized to allow the discrimination of more than two group. Discrimination of more than two groups requires more than one discriminant function be generated. In practice, for k groups, k-1 discriminant functions are needed to differentiate the groups. Discriminant function analysis can be thought of as a rotation of axes to find the orientation that best separates the two groups.
The discriminant function problem can be written in matrix format as:
D = Cov(X)*W
Where D represents the vector of mean differences between the centroid (multivariate center) of groups 1 and 2 measured on k variables. Cov(X) is the pooled covariance matrix for the variables in group 1 and 2. This matrix has dimensions of (k x k), and W represents a vector of k discriminant weights. The relationship can be solved for w by least squares. This amounts to minimizing the variance within a group while maximizing the distance that separates the centroids of the two groups.
Although the choice of symbols is not as standardize as for other methods, the general form of the solution to the discriminant function problem is:
ds = wo + w1x1 + w2x2 + w3x3 + .. + wkxk
were ds is a discriminant score for each sample (sometimes denoted with an R or L), and w1 through wk (sometimes written as b's or lambda's) represent the discriminant weights for variables x1 through xk (sometimes written as psi). Despite the choice of symbols, this relationship should look very much like the generalized multiple linear regression equation!
Like regression, a model can be generated either with or without an intercept. Discriminate function analysis differs from regression analysis in one important respect. In regression we seek to find the coefficients that best relate a single y variable to one or more x variables. In discriminant function analysis, we seek to find coefficients that best define the average distance between the multivariate means of two or more groups on the basis of two or more x variables. For this reason, Kachigan describes discriminant function analysis as a regression problem with continuous x variables and a category y variable.
Once we have established a discriminant function, we can
use it to sort new samples into
the appropriate groups. This is done by comparison of
the discriminant scores (ds) for each sample against a critical discriminant
score. The centroids for each group have discriminant scores defined
as ds1 and ds2 respectively. These can be found by substituting the vector
of mean values for group 1 and group 2 into the discriminant function to
get ds1 and ds2 respectively. The distance between the centers of
the two vectors is know as "Mahalanodis' distance" or the
standardized squared distance between the groups. The critical discriminant
score (dso) is defined as the midpoint between the centroids of the two
groups. This is found by substituting the mean of the group means into
the discriminant function.
Sorting the data on the basis of the discriminant scores is relatively easy. Samples with discriminant scores greater than dso belong to one group. Samples with discriminant scores smaller than dso belong to the other. In practice, some fraction of samples tends to be misclassified due to overlaps in the variance of the two or more groups.
There are several assumptions that must be met for the discriminant function analysis to be valid:
1. The random x variables must be normally distributed for each group.
2. The probability of an unknown sample belonging to any group is equal.
3. The variances and covariances of the variables in each group must be equal.
4. None of the samples used to calculate the function were misclassified.
As with multiple linear regression, the discriminant functions can be found using forced, or stepwise procedures (forward, backward or all function methods). See the multiple linear regression notes for additional detail.
The discriminant function problem suffers from drawbacks similar to that of multiple linear regression: instability of discriminant weights and colinearity (see multiple regression problems). Despite this, it does not appear to be customary to calculate confidence intervals for the discriminant weights or discriminant scores. Nor is it customary to calculate measure of error such as the rmse. The errors in the model are generally reported as percentages of misclassifications, that is members of group one assigned to group two and vice versa.
The best way to avoid potential problems with the method is to:
(1) Be aware of the degree of correlation between the x variables. Avoid using variables that are obviously highly correlated.
(2) Use a stepwise procedure for model development.
(3) Always test the model using independent data to determine
if the terms in the
equation are valid. This is often referred to as a cal-val
strategy. Use one data set for calibration, and a second for validation.
A third problem inherent in multiple linear regression arises from a weakness of the least squares procedure. As we add each additional term to the equation, the remaining residual variance in y must always decreases. Some of this decrease is due to a true relationship, but some of it is due to random chance. Our best defense against this problem is to use the approaches described in 2 and 3 above.
The greater the distance between the multivariate means of the k groups, the greater the potential significance of the discriminant function. Significance of the model is based on an F-ratio in the same was as for ANOVA or regression analysis. (See the lecture notes on ANOVA analysis and Multiple Regression Analysis for additional information). The numerator of the F-ratio has k degrees of freedom where k is the number of variables, while the denominator has (N - k-1) degrees of freedom, where (N = n1 + n2) is the combined number of samples in both groups.
{kind=link}
{kind=link}
{kind=link}